
[摘要] 人用经验是中医药临床实践的总结,也是中药新药研发中评价中药安全性、有效性和临床价值的重要数据来源。 收集和总结中药人用经验数据,应用相关统计分析,形成可用于评价的证据是中药人用经验研究关键一环。该文尝试归纳并 探讨目前中药人用经验的临床数据特点和统计分析方法,对数据类型、结局评价、偏倚评估、混杂因素及缺失值的处理逐一进 行总结。该文强调中药人用经验的数据分析对于中医药证据形成的重要性,同时提出了目前的难点,如数据质量不高,内部 差异性大;缺少个体化数据处理方法;缺少“病证结合”中医特色数据的方法等。相信随着相关方法的规范化和科学化,中药 人用经验数据能为中药新药的研发提供有力的证据。
近年来,国家发布了一系列政策文件指导中医药工作, 明确将中药新药研发作为中医药发展的重点任务之一,为中 药新药研发带来了历史性机遇[。其中,中药注册分类的配 套文件强调了人用经验的重要性,基于悠久的历史传承和广 泛的使用,人用经验是中医药的独特优势,为中药新药的研 发提供了有力的佐证[2]。
目前《中药注册分类及申报资料要求》中明确基于古代 经典名方、医疗机构制剂、名老中医方等具有人用经验的中 药新药审评技术要求,加快中药新药审批,根据处方来源和 组成、临床中药人用经验及制备工艺情况等可适当减免药效 学试验3]。中药人用经验的主要来源是古籍医案、医疗机构 制剂及名老中医等专家经验方。但是"人用经验"不直接等 同于堆砌的“人用数据”,而是需要通过严谨的论证总结为 “人用证据”[24]。因此,从临床经验数据中评价疗效、形成证据是中药人用经验中重要的一环。
目前,药物疗效评价主要是基于随机对照临床试验,分析 药物效果得出证据。然而中药人用经验的临床数据类型比较 复杂,主要是以个体医案、病例等累积而来的临床数据,混杂 因素众多,其分析方法显得多样而复杂5]。因此本文试论述 中药人用经验中临床数据以及分析统计方法,供同行参考。
1 临床数据类型
由于中医药已经广泛在临床上使用,相关的临床试验设 计更倾向于实用性而非解释性,因此各种类型实用性临床试 验(PRCT) 更加契合中医药的临床设计原则[6]。但在大多数 情况下,中药人用经验的临床数据没有预先的干预设计,所 以一般更多采用观察性研究的方法来评估药物效力。而根 据观察人群是否存在对照组,又可以把观察性数据分为观察 类试验性数据和非试验数据,见图1。
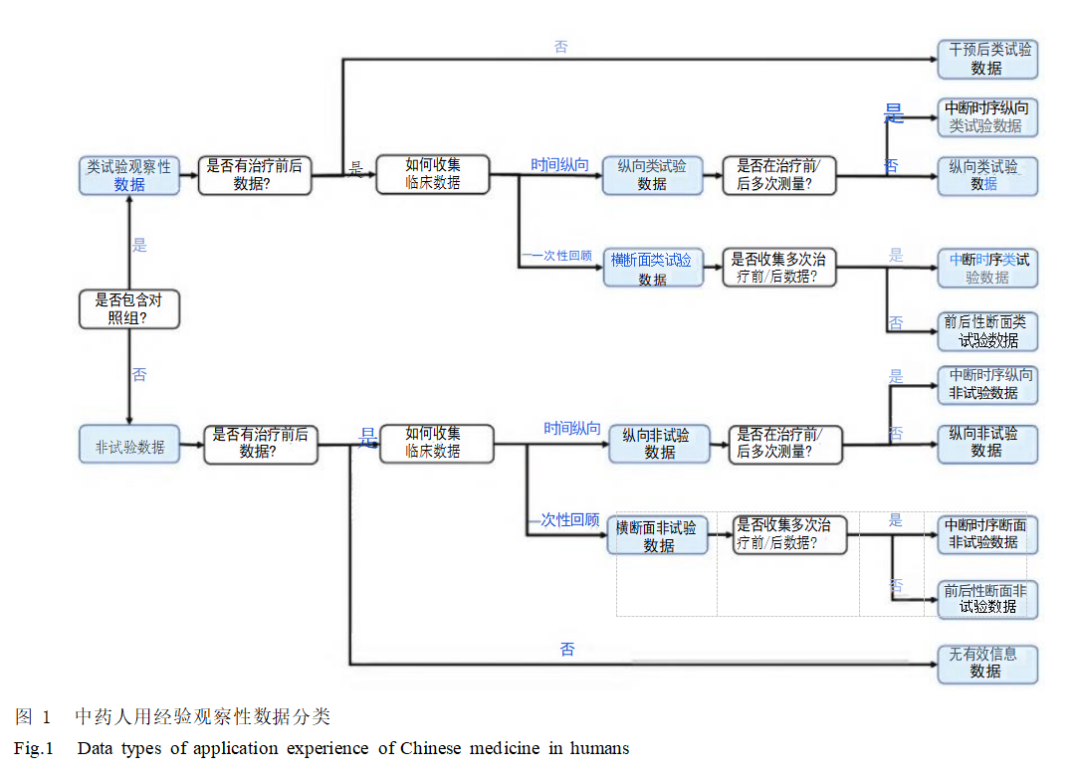
1.1 类试验观察性数据 临床试验的目的是确定药物疗效 (effectiveness),其特征必须包含干预组、对照组,以及2组干 预前和干预后的数据。观察性研究并没主动干预,但是含有 中药治疗人群和对照人群,以及2组干预前和干预后的数 据,因此把含有这4种元素的临床数据称为类试验观察性数 据,用于评估药物效力 (efficacy)。干预前/后的数据如果 是 不 同 时 间 点 分 别 收 集 , 则 为 纵 向 数 据 (longitudinal observational data),如果依靠回顾一次性记录,则为断面数据 (cross-sectional data)[8]。 在纵向数据中,如果满足的基本条 件,即治疗前后记录相关指标,则为纵向类试验数据 (longitudinal pre-post data)。如果治疗前和治疗后多次重复 测量数据,则为中断时序纵向类试验数据 (longitudinal interrupted time series data)⁹。在观察性研究中,中断时序 纵向数据由于可以矫正时间依赖性偏倚,因此在评估中药疗效的内部效度(药物与疗效的因果关系)方面较好。虽然断 面数据质量整体不及纵向数据,但是也能为中药疗效的内部 效度评估提供一定信息[0]。在断面数据中,也可以根据多 次,或者一次性收集治疗前后的结果,分为中断时序断面数 据(cross-sectional interrupted time series data)和前后性断面 数据( cross-sectional pre-post data),前者的数据质量优于后 者。如果数据仅仅提供治疗后信息,则会混入大量混杂信 息,几乎不能评价治疗与结局之间的因果。
1.2 非试验数据 在实际的临床数据中,往往有大量的医 案、门诊病历等数据,这些数据缺乏对照组,因此为非试验数 据。相比于类试验观察性数据,非试验数据对于疗效评价, 以及中药-疗效的因果关系推论要弱,然而在中药人用经验 中,绝大部分数据都为非试验性,合理收集这些数据,归纳分 析结果仍可能为后续的临床试验设计提供不少佐证[7, 非试验数据根据数据记录时间,以及是否重复测量,同样可 分为中断时序纵向数据、纵向前后数据、中断时序断面数据 以及前后性断面数据4种。其中纵向数据能提供的信息很 为优质,即使在非试验数据中,采用与目标值对比的方法,时 序纵向数据也能在一定程度上评估中药的疗效和安全 性[12]。相反,横断面数据由于患者的状况会随时间变化,或 其混入其他因素,可能会导致严重的信息偏倚。因此在收集 临床数据时,应注重保存类试验观察性数据。而在缺少对照 组时,也应该保证有治疗前后的数据,避免回顾性记录而产 生偏倚。
2 结局及安全性评价
结局指标是评价药物疗效的核心数据。在中药人用经 验中,既要考虑临床评价利用度,又要顾及中医药自身实践。 一般建议在中药人用经验的疗效评价上,主要结局还是采用 国际公认的结局指标,次要结局可选取报告结局(PRO), 用 于评估患者生命质量等[13]。中药人用经验数据一般采用病 证结合记录,证候评分是中医药数据的特色,但证候评分与 重要疗效的关系要谨慎处理,评分的高低与患者实际的疗效 获益不一定呈绝对相关[14]。结局指标选择可以参考高质量 指南、系统综述或随机对照试验等,也可以参考国际核心结 局指标集,如 COMET 核心结局等。此外在循证基础上,应该 鼓励完善和应用中医药相关的核心指标集进行疗效 评价[15]。
安全性的评价是中约人用经验数据的一个重点,也是其 薄弱环节[16]。在平时的临床记录中,往往忽视不良事件的 记录, 一些不合理的低不良事件率在很多时候是由于没有合 理记录造成。因此平日需加强病历临床数据管理,规范不良 事件的定义和等级,平时按照要求上报和处理。在规范化方 面使用如 MedDRA、WHOART、ICD10 等统一标准的不良反 应编码惯例或字典[17-18
在结局统计方面,中药人用经验临床数据包含大量混杂 因素,因此需要通过多种方法对药物的效力值进行矫正。即使应用了分层、匹配和模型矫正后,对结果的解读也需要慎 重,此时得出的统计结果可以为后续临床试验作为参考,但 不能直接解读为药物的疗效或者效力[1921]。此外,中药人用 经验数据的类型和统计目的与临床试验有较大差别,由于没 有预先设定临床有效阈,且样本量较多,基于中药人用经验 的统计往往会出现有统计学意义,而无临床意义的情况(如 某种中药确定有降压作用,但是由于作用太弱没有应用价 值)。因此中药人用经验数据的统计结果应注重描述性统 计,强调结果的临床解读而弱化统计学意义,为后续试验提 供更多的信息[22]。对于病案记载的中医证候,可应用评分 工具进行评估,并建议采用标准化差异统计,用于排除偏倚。 对于多个互相不能重合的结局,应该选择竞争风险模型 competing risk model),考虑多种潜在结局来评估药效,避免 错误估计药物对某种结局的效果[23]。
3 偏倚评估
相对于设计良好的临床试验数据,中药人用经验数据由 于没有良好的质控,往往存在较大偏倚。中药人用经验数据 可见各种选择性偏倚和信息偏倚,如仅在医院收集临床经验 数据,会出现伯克森偏倚[2];中医药证候结局具有多样性, 仅观察一种证候结局时,可能造成竞争风险偏倚[25];而信息 偏倚在中药人用经验数据中更为常见,如回忆偏倚、报告偏 倚、诱导偏倚等。而临床记录的不规范,则会产生药物暴露 错分和结局错分偏倚[26]。
对于选择性偏倚,在数据收集、筛选流程和细节上要谨 慎设计,制定相应的纳入排除样本标准,明确每种偏倚产生 的原因和每个步骤可能产生的偏倚,以提高样本的可分析 性[27]。对于信息偏倚,应尽量提取相同指标的重复测量信 息,并采用回归稀释方法评估测量误差并对其校正。对于矛 盾数据需要溯源,查看原始医案/病历记录。对于异常值,需 要在统计分析计划中预先制定敏感性分析的方案,并依次在 统计分析报告中进行异常值的敏感性分析。此外还有来源 于混杂因素的偏倚,由下面单独讨论[26]。
4 混杂因素处理
混杂是指干预对结果的影响(或关联)被另一个变量的 存在所扭曲的情况,是数据偏倚产生的重要原因之一。由于 混杂因素与药物干预/疗效单独相关,因此在评估时常常扭 曲干预和结果之间实际关系,从而导致错误估计中药疗效。 控制混杂因素好的方法即是随机对照过程,通过随机分组 可以使比较基线相等,排除混杂因素。然而由于中药人用经 验的临床数据多为观察性,且数据的来源、质控均不严格,因 此混杂因素问题可能是中药人用经验数据分析的一大难点, 需要重点处理[28-29
在识别混杂因素方面,需要紧密结合临床知识,尽可能 纳入并矫正潜在对药物疗效有影响的因素[30]。由于中药 人用经验数据质控问题,可能存在较多未知的混杂因素,超 出临床医师的判断范围,此时可以结合一些统计学方法,如传统的逐个相关性分析法,结合有向无环图分析因子之间 的关系,从而判断是否为混杂因素[31]。此外一些机器学习 的方法,如 Lasso 回归的手段可分析各个因子对疗效结局的 影响力,XGBoost算法可计算各种因子组合对疗效的贡献 度[32]。基于这些方法配合知识,能更好地识别出混杂 因素。
在矫正混杂因素方面,对于连续性变量的结局指标, 一 般采用前后差值,或协方差方法来防止基线偏倚,或采用更 为稳健的中断时序设计矫正基线[33.34]。在数据量较大情况 下,对于潜在因素应多分层,分层除了可以较好矫正混杂因 素以外,还可以继续分析药物和其他因素的协同作用。此 外,还可以依靠各种统计工具对混杂因素进行矫正,见表1。 各种回归模型是矫正混杂因素的常用方法,如应用多重线 性回归处理连续性数据资料,应用Logistic 回归处理一般分 类资料,应用 Poisson 回归处理偏态分布资料,应用Cox 回归处理生存资料等[35-36]。回归分析可以同时考虑多个因素的 作用,排除混杂因素的影响,但是要求结局事件的例数不能 太少。此外可以用随机匹配法,使中药组和对照组之间具有 可比性,而常用的匹配方法为倾向性评分法(propensity score method)[20]。 倾向性评分法可针对混杂因素进行模拟 拟合后打分,根据分数相似度进行匹配,使2组基线相近。 除了直接匹配,利用倾向性评分还可以进一步联合分层、回 归、加权等方法矫正混杂因素,相比于回归法,倾向性评分可 以用于混杂因素较大,样本数量较小的数据,但难以像回归 方法构建矫正以后的中药量-效的非线性关系[3]。中药人用 经验数据往往包含大量的未知混杂因素,对其处理也一直是 业界的难题之一。工具变量(IVA) 分析是处理未知混杂因 素的常用办法,如孟德尔随机化设计就引入了基因型这一工 具变量[38]。但是在中医药的研究中,如何寻找合适的工具 变量,仍然存在争议和困难。
5 数据缺失处理
不同于临床试验数据,中药人用经验数据由于没有统一 规范设计,存在大量缺失值,因此对于缺失值的处理是中药 人用经验的必经环节。缺失值可以根据数据内部随机属性, 分为完全随机缺失、随机缺失和非随机缺失3种[3]。 一般 来说对于完全随机缺失,其结果不依赖任何其他变量,因此 可直接对样本进行填补,如应用LOF 方法、多重插补法或回 归方法进行变量填充[40]。但是在中药人用经验临床中,由 于记录的模式问题,绝大多数缺失都存在非随机性(如医院 或者个人记录的偏好,中医医案的风格导致),如果直接删除 或用传统方法填补,可能会造成偏倚[4]。因此这时可利用 模式混合模型(pattern mixture models)进行插补,但是由于此 方法需要的样本量较大,因此还需要对缺失值进行敏感性分 析,从而保证缺失填充的准确性[42]。
6 问题与展望
目前在中药人用经验临床数据的处理和统计中,存在不 少问题和难点,如记录质控不高、规则不统一、标准和指标难以收集和归一化。诸多中医药个性化数据,如如何在数据收 集和分析中合理处理组方配伍、量效关系等因素;如何纳入 并统计评估中医药特色的指标,实现“病证结合”;如何构建 中药人用经验临床证据等级的评估等。但尽管存在这样和 那样的问题,作者相信随着国家的重视,交叉学科的融入以 及新方法的推广,这些问题会逐个得到解决,中药人用经验 数据收集和处理过程将会更加科学、严谨,形成规范,指导中 药新药的研发。


